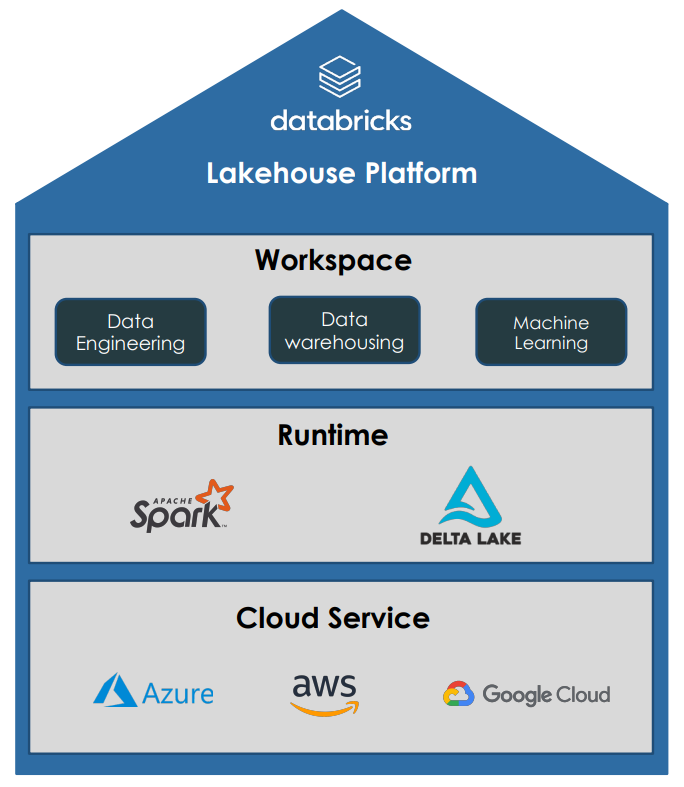
Databricks is a multi-cloud lakehouse platform based on Apache Spark that covers the entire data processing process: data engineering, data science and machine learning.
Databricks is offered on the largest cloud platforms Microsoft Azure, Google Cloud and Amazon AWS. The Databricks environment manages Spark clusters and offers interactive notebooks for processing, analysing and visualizing data in multiple programming languages. The creation and control of jobs and pipelines also enable the automation of data processing.
Apache Spark
By using Apache Spark as a framework for data processing, Databricks is suitable for analyzing big data and developing machine learning models, as Spark uses clusters with a large number of servers for data processing, which offer almost unlimited computing power through scaling. Spark also offers an interface for programming in various languages, such as Java, Scala, Python, R or SQL.
Delta Lake
Delta Lake is an open source storage layer designed for managing big data in data lakes. Delta Lakes increase the reliability of data lakes by improving the data quality and consistency of big data and adding functionality from traditional data warehouses. Delta Lakes support ACID transactions, scalable metadata and time traveling by logging all transactions. Delta Lakes are also Spark compatible and use standardized data formats such as Parquet and Json.
Delta lakes thus enable the creation of a lakehouse that combines the advantages of data lakes and data warehouses.

MLflow
MLflow is an open source platform for managing the entire machine learning lifecycle. It is designed to simplify the process of training, managing and deploying machine learning models. MLflow enables the logging and tracking of machine learning experiments during model training and the easy deployment of trained models as Docker containers, Python functions and RESTful API endpoints. MLflow is compatible with various machine learning frameworks such as TensorFlow, PyTorch, Scikit-Learn and XGBoost. It can be used in Jupyter Notebooks, Apache Spark, Databricks and AWS SageMaker, among others.
Worksflows
Databricks workflows are used to orchestrate multiple tasks that can be defined, managed and monitored as ETL, analytics or ML pipelines. The individual tasks within a workflow can execute Databricks Notebooks, SQL queries or Delta Live Table pipelines. By setting predefined times or triggers to execute batch jobs, recurring tasks can be automated and the implementation of real-time data pipelines enables the continuous execution of streaming jobs. The use of a job cluster reduces computing costs as they are only executed when a workflow is scheduled. The Databricks workspace provides a complete overview of the executed workflows and optional notifications via email, Slack or webhooks.
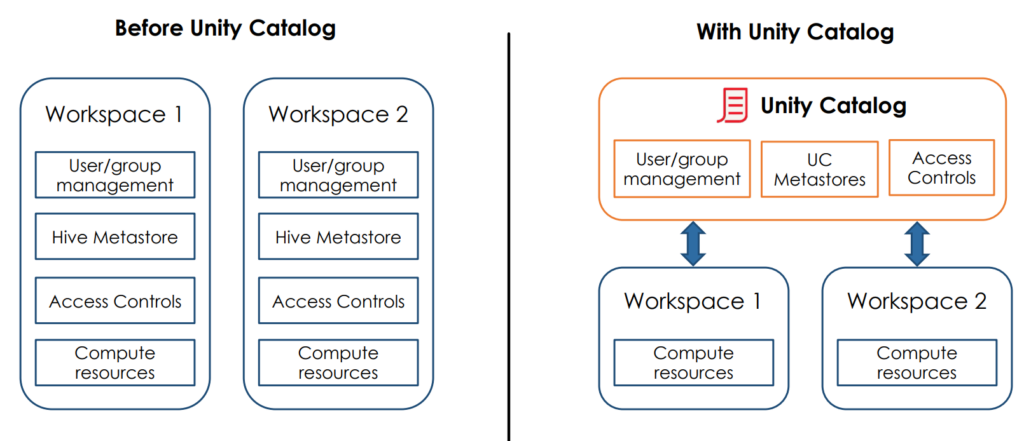
Unity Catalog
Unity Catalog provides a unified governance solution for data and AI resources in Databricks. This includes centralized functions for access control, monitoring and provenance determination of data in Databricks environments. With Unity Catalog, data access policies can be defined centrally so that they apply to all workspaces. Unity Catalog also provides an interface to search for data objects and capture provenance data to track how data resources are created and used.
Application example: Analysis of data from online retail
Each Databricks workspace has a distributed file system that is pre-installed on Databricks clusters. This Databricks File System (DBFS) provides an abstraction layer for storing data in underlying cloud storage. This allows objects from the cloud storage to be addressed with relative paths in the semantics of a file system without the need for cloud-specific API commands. The DBFS also contains some test data sets, such as a data set with sales data from online retail.
The Magic command %fs can be used to access the DBFS in order to display the available files.

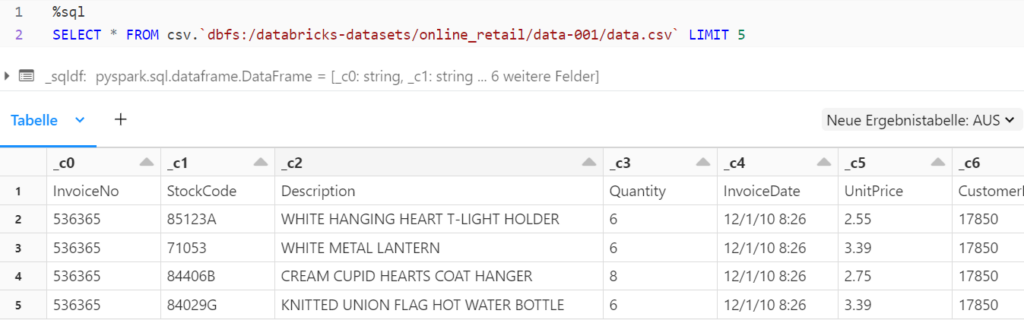
The data in a file can be read out using an SQL query. The following SQL command is used to display the raw data directly from the file:
SELECT * FROM fileformat.`filepath`
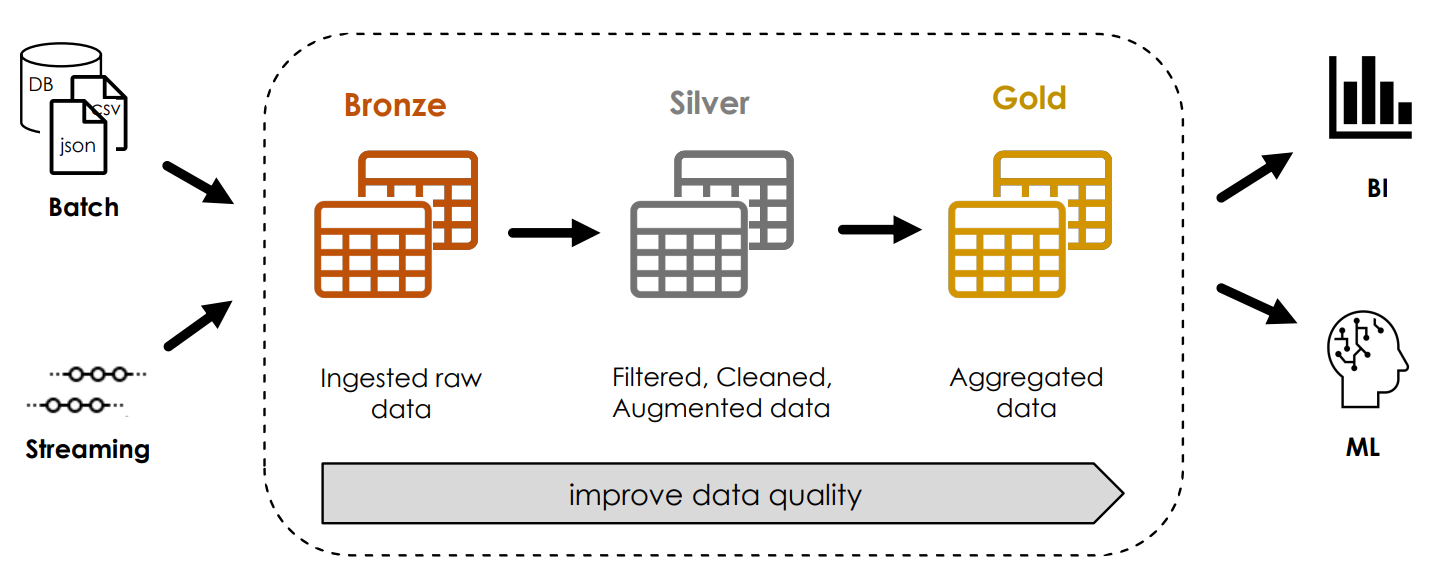
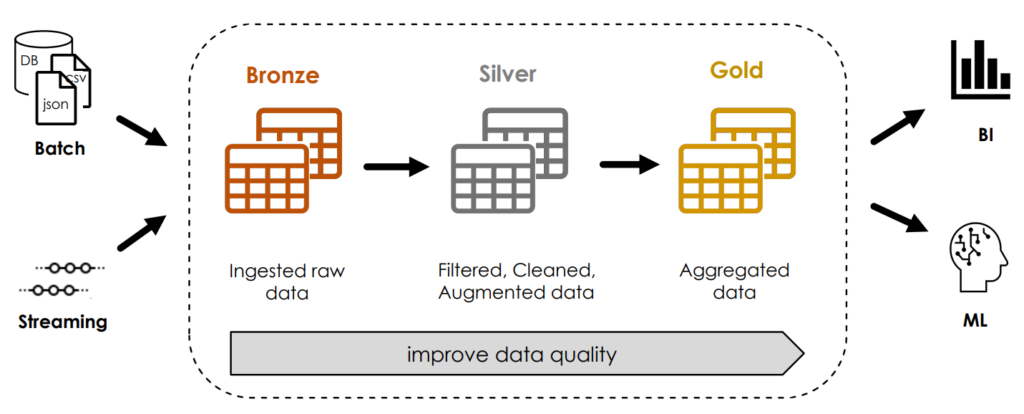
Structure of a multi-hop architecture
In a multi-hop architecture, which is also known as a medallion architecture, the structure and quality of the data is improved incrementally. To this end, a bronze table is first generated with the raw data so that the original data can be reprocessed at any time without having to read the data from the source system again. The silver table then contains the cleansed data, on the basis of which several gold tables with aggregated data for machine learning or business intelligence can ultimately be created.
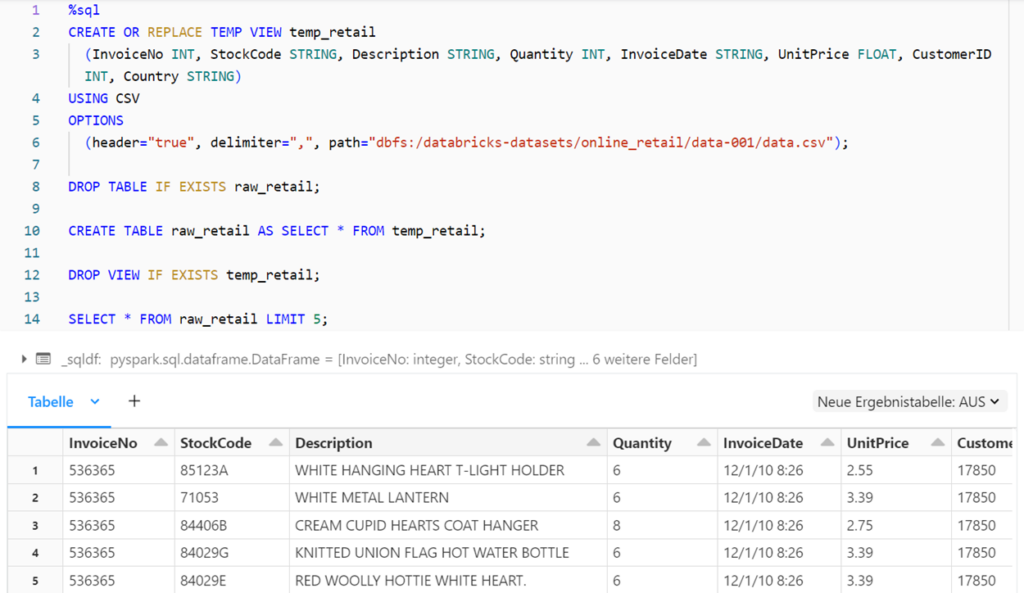
With the above method for reading the raw data (SELECT * FROM fileformat.`filepath`), the schema of the table is automatically developed and there is no possibility to specify further file options. To create a delta table with a defined schema and the specification of file options, a temporary view and a table based on it are therefore created using the CTAS command (CREATE TABLE AS SELECT).
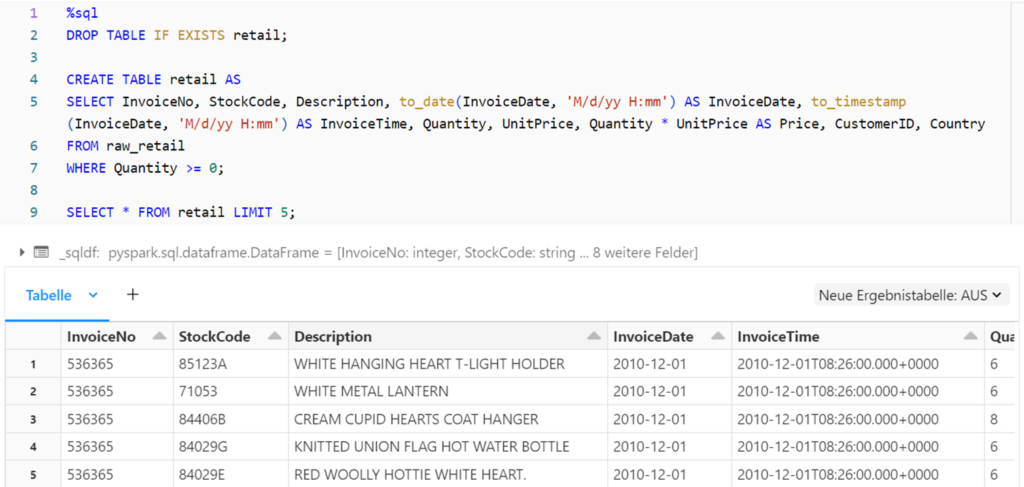
The silver table is then generated from the bronze table using the CTAS command. The dates are formatted, a new price column is created by multiplying the unit price by the quantity and the data is filtered so that only rows with a sales quantity of at least zero are taken into account.
A view is created for the gold layer, whereby the data is grouped according to the invoice number and the total price is determined for each invoice. In addition, the invoice date is divided into the day, hour and minute of invoicing.
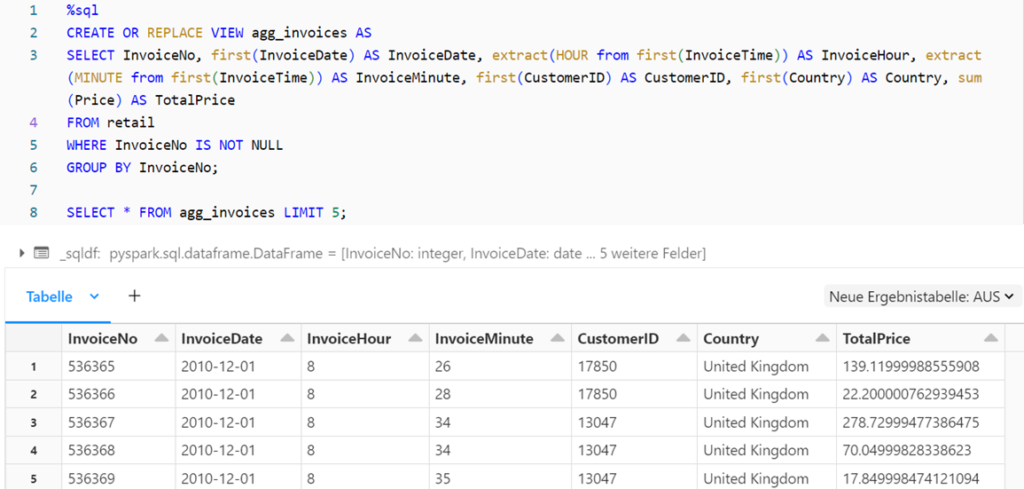
Visualization of the data in Databricks
The silver table and the aggregated data from the gold layer can now be used for analysis and visualization. Databricks Notebooks offer the option of visualizing the results of an SQL query using an editor.
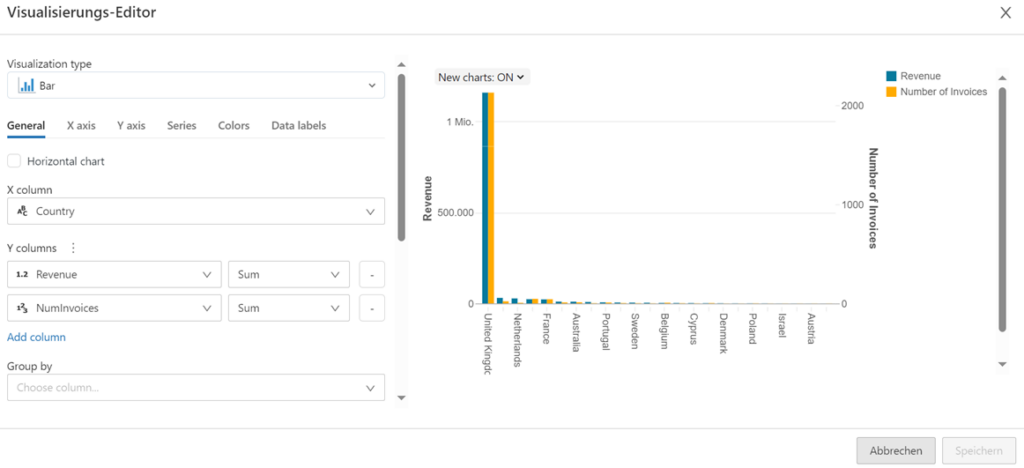
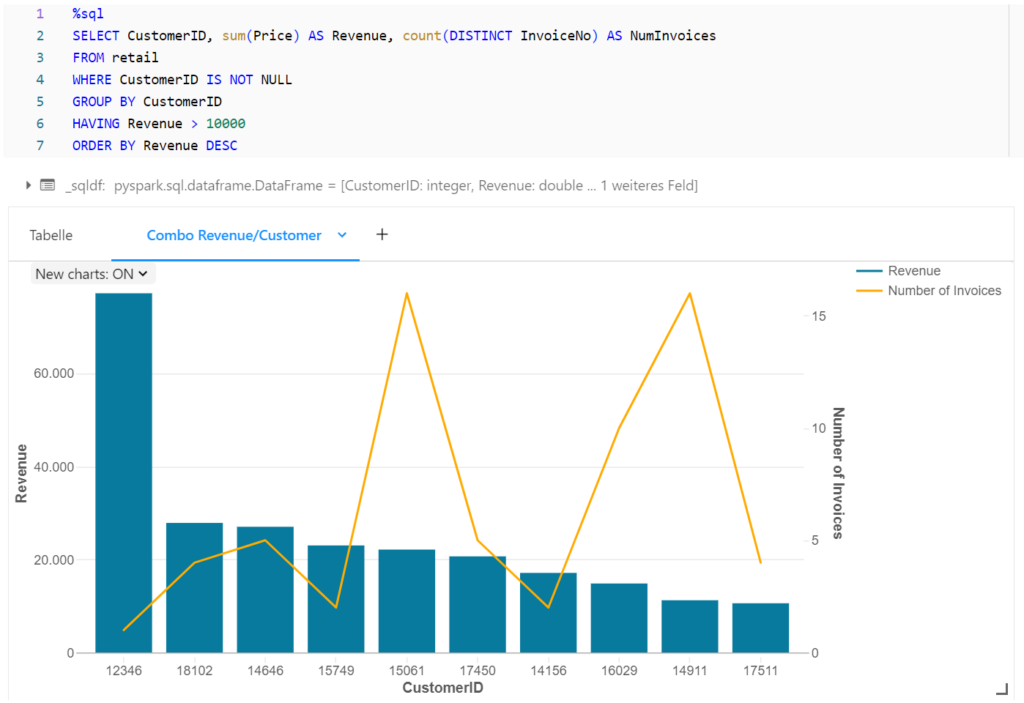
For example, in the next figure, the invoices are grouped by customer in order to visualize the total turnover and the number of invoices for the customers with the highest turnover.
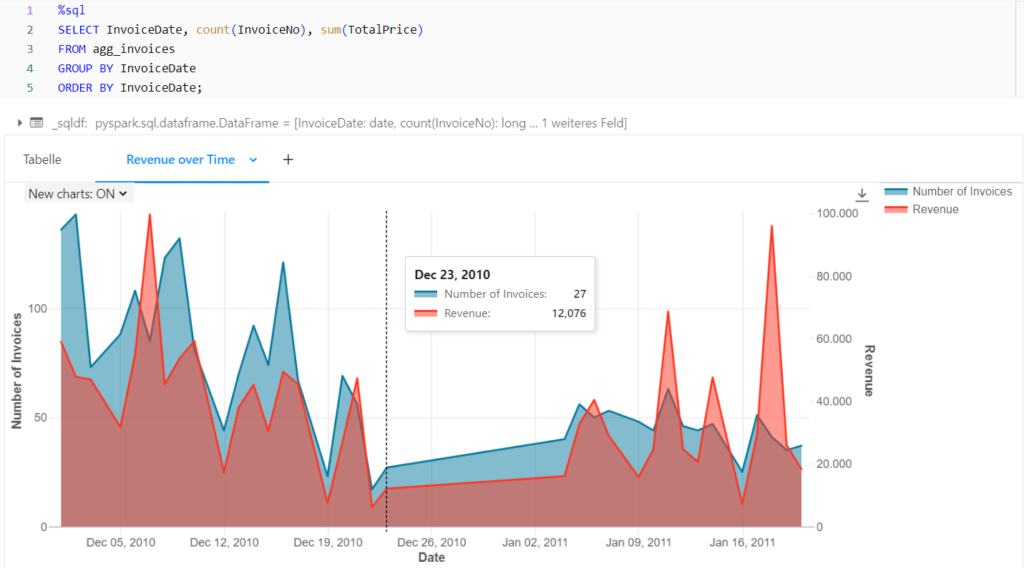
Based on the gold table aggregated by invoice, the turnover and the number of invoices per day can also be displayed over time.
Conclusion Databricks
Databricks uses Spark clusters and interactive notebooks to integrate, process, analyse and visualize large volumes of data. The Lakehouse architecture enables the creation of a flexible data warehouse and machine learning models can be developed in Databricks with the help of MLflow. Workflows are also used to orchestrate and automate data processing, while Unity Catalog provides a unified governance solution for Databricks environments.
Interested in Databricks? Take a look at the Data Strategy Assessment or the Databricks Showcase.


